
AI diagnosis studies routinely report 95%+ accuracy, but a 2024 Lancet Digital Health meta-analysis found fewer than 15% of those studies could be independently reproduced, and Brigham deployment data shows 20 to 35 point accuracy drops in live EHR use. The headline says AI beat doctors at diagnosis. The study says AI matched a small panel of generalists on a hand-picked dataset under conditions that look nothing like your ED at 2am.
Definition anchor: The NEJM AI Diagnostic Benchmark is a controlled-environment performance evaluation that measures model accuracy under conditions that do not replicate real-world clinical deployment. That distinction is the entire ballgame for any healthcare leader making a procurement call on diagnostic AI in 2026.
TL;DR / Key Takeaways
- The headline "AI outperforms doctors at diagnosis" is technically accurate in a narrow lab setting and almost certainly misleading for your deployment decision.
- Most benchmark studies test AI on hand-picked, pre-labeled datasets, not the messy, incomplete, multi-source records your EHR actually produces.
- "Accuracy" in a study can mean sensitivity, specificity, AUC, or top-1 match rate, and vendors routinely pick whichever number looks best.
- Diagnostic AI bias against minority populations, elderly patients, and rural documentation patterns is documented and underreported in press coverage.
- Healthcare leaders who deploy diagnostic AI without a site-specific clinical AI validation protocol are taking on clinical and legal risk that no vendor SLA covers.
What everyone is saying about AI diagnosis right now
The dominant narrative is hard to miss. AI models trained on massive datasets now match or exceed radiologist, pathologist, and ED physician accuracy on a range of diagnostic tasks: skin lesion classification, diabetic retinopathy screening, pneumonia detection, sepsis prediction. The STAT News piece in May 2026 was the proximate trigger for the latest cycle, and the vendor and media amplification machine did the rest.
The takeaway most healthcare tech buyers are walking away with: AI is ready as a diagnostic co-pilot or even a primary screening layer, and organizations dragging their feet are falling behind. The emotional pull is real. Diagnostic error kills an estimated 40,000 to 80,000 Americans annually per AHRQ ranges. Everyone wants the silver bullet. The hope is reasonable. The evidence is being overstated.
Yes, repeatedly. The pattern across Q1-Q2 2026 vendor conversations we've been adjacent to in BH/SUD looks roughly the same. Vendor leads with a single accuracy number, usually north of 90%, almost always sourced from their own internal benchmark or a co-authored study they funded.
The most common construction is "our model matched or exceeded clinician performance on [specific task]" without specifying the task narrowness, the comparator setup, or the patient population. See our breakdown in vendor benchmark red flags for the recurring tells.
In the ambient AI scribe and AI documentation category specifically, Eleos, Blueprint, Abridge, Ambience and adjacent players, we've seen pitch material that cites clinician time savings of 30-60% and "documentation accuracy" figures in the 92-97% range. What's almost never in the deck is the definition of accuracy being used, the operating threshold, or the subgroup breakdown. The buyer hears "97% accurate." The footnote, if there is one, says "on internal validation set, n undisclosed."
Practice owners and COOs we talk to take those numbers at face value because they're under margin pressure and the math looks too good to walk away from. That's not a knock on them. It's a knock on how the category sells.
Why is the consensus on AI diagnosis wrong?
The dataset problem. Benchmark studies use retrospective, fully-labeled, single-source datasets. Real clinical records are incomplete, multi-format, contradictory, and drawn from 3 to 7 different systems. Test an AI on a clean ImageNet-style medical dataset, then call it production-ready, and you have not proven what you think you have proven.
The comparator problem. "Doctors" in these studies are often a small panel of generalists asked to diagnose from the same pre-packaged data slice the AI sees. No patient history. No follow-up. No clinical intuition from a 10-minute exam. That is not how your hospitalists work. The comparator is not fair.
The metric shell game. Study reports accuracy. Vendor press release reports accuracy. But accuracy on a 95/5 class-imbalanced dataset can be gamed to 95% by predicting "healthy" every time. AUC, sensitivity at fixed specificity, and F1 score are what matter. Vendors do not lead with those.
The bias documentation gap. Multiple peer-reviewed analyses (Stanford HAI, MIT CSAIL, NEJM AI editorial board) have flagged that diagnostic AI models systematically underperform on Black patients, female patients under 50, and patients with comorbidity stacks common in safety-net hospitals. The headline study probably did not stratify by these subgroups, or buried the stratification in supplementary tables.
The regulatory non-endorsement. FDA 510(k) clearance for a Software as a Medical Device diagnostic tool means the device is "substantially equivalent" to a predicate. It does not mean FDA validated the accuracy claim in your patient population.
Yes, though the cleaner framing for our work is AI documentation rather than diagnostic AI, since that's where BH/SUD facilities are actually deploying right now. Adentris reviewed BH/SUD records across multiple client facilities where an AI scribe or AI-generated note structure was in the clinical workflow. The recurring failure pattern is the same. The AI-generated note reads clean, the chart looks complete on the surface, but the documentation doesn't actually support the level of care being billed.
A few specific patterns we see repeatedly:
- ASAM dimension scoring that's present in the AI-generated note but not tied to the clinician's own observations, which collapses on UR review.
- Group therapy notes that are auto-generated from a template and end up looking nearly identical across patients in the same group session, a clear audit flag.
- Discharge summaries where the AI carries forward language from intake that no longer reflects the patient's actual progress, creating a documented contradiction with the treatment plan.
None of this shows up in the vendor's accuracy benchmark. All of it shows up in a payer audit.
What does the research actually show about AI diagnosis?
Steelman first. In a controlled setting, on the specific task it was trained for, with the specific imaging modality it was optimized on, the model probably does perform at or above the comparator physician group. That is a real and meaningful result for that narrow use case.
Diabetic retinopathy screening in high-volume, single-modality, well-labeled populations is the canonical example. Radiology triage for obvious findings in standardized imaging pipelines is another.
The reproducibility gap is enormous. A 2024 meta-analysis published in The Lancet Digital Health found that fewer than 15% of AI diagnostic studies reported enough methodological detail to be independently reproduced. "We can not replicate your result" is not a headline. "AI beats doctors" is.
Most AI clinical studies would not pass the evidentiary bar we require for a new drug. We are approving algorithms with less rigor than we apply to aspirin., Eric Topol, MD, Scripps Research Translational Institute, 2024
Studies from Brigham and Women's Hospital and University of Michigan that tracked diagnostic AI from benchmark to clinical deployment found 20 to 35 percentage point accuracy drops when the model hit live EHR data. The benchmark number is a ceiling, not a floor.
Adentris audited BH/SUD documentation QA reviews across anonymized client records using AI-assisted notes. The pattern we observe is roughly 15 to 25% discordance between the AI-generated clinical content and what a defensible coded claim actually requires. That's not "the AI got the diagnosis wrong." That's "the AI-generated note doesn't carry the documentation weight the code billed against it needs."
To be clear about what that range means and doesn't mean: this is pattern data across our reviews, not a published study. Discordance varies by facility, by EMR, and by which AI tool is in the workflow.
We've seen facilities at the low end (under 10%) where clinicians heavily edit AI output before sign-off. We've seen facilities at the high end (over 30%) where AI output gets accepted with minimal review and the documentation gaps compound across the patient episode. The takeaway isn't the exact number. It's that the gap exists, it's material, and no vendor benchmark surfaces it because the benchmark isn't testing for it.

| Dimension | Benchmark Study | Your Deployment |
|---|---|---|
| Dataset | Hand-picked, pre-labeled, single-source | Multi-source EHR, incomplete, contradictory |
| Comparator | 3-5 generalists, no patient context | Specialists with full clinical picture |
| Subgroups | Often unstratified or buried in appendix | Medicaid-heavy, comorbidity-heavy panels |
| Monitoring | Single point-in-time evaluation | Required ongoing drift detection |
| Regulatory | 510(k) substantial equivalence | Site-specific validation expected |
Why does the wrong view persist?
Vendor incentive is obvious. A company with a diagnostic AI product has every reason to amplify the most favorable study interpretation. Their sales cycle depends on it. Not malice. Capitalism. Healthcare leaders need to account for it.
Media incentive compounds it. "AI matches doctors in narrow controlled study with methodological caveats" does not get clicks. "AI beats doctors" does. Science journalism covering AI has a documented optimism bias. Healthcare AI is not the exception.
Hospital buyer incentives create demand-side credulity. C-suites under margin pressure want a silver bullet. A study showing AI outperforms doctors is a permission structure to cut costs.
Scrutinizing the methods would complicate a decision the CFO already wants to make. Publication bias toward positive findings is documented across medicine. Studies showing the model failed rarely make NEJM.
Yes. The most common procurement path we see in BH/SUD generalizes to broader healthcare based on what peers in the space describe. The AI tool gets purchased before any validation framework is in place. The trigger is almost never a methodologically rigorous review. It's one of three things:
- A vendor demo that showed well in a 30-minute Zoom, often using cherry-picked patient examples.
- A peer referral from another facility owner or COO who deployed the same tool and said "it works", without a defined metric for what "works" means.
- A board member or investor who flagged a competitor adopting AI documentation and pushed the leadership team to match.
In none of these procurement triggers is there a site-specific validation protocol, a baseline error rate measurement, or a defined performance floor with remediation language in the contract. The validation question gets raised, if at all, six to nine months into deployment, usually after the first denial pattern or audit finding traces back to AI-generated documentation. That's the wrong order of operations, and it's the norm, not the exception. See our AI governance healthcare playbook for the procurement checklist we use with clients.
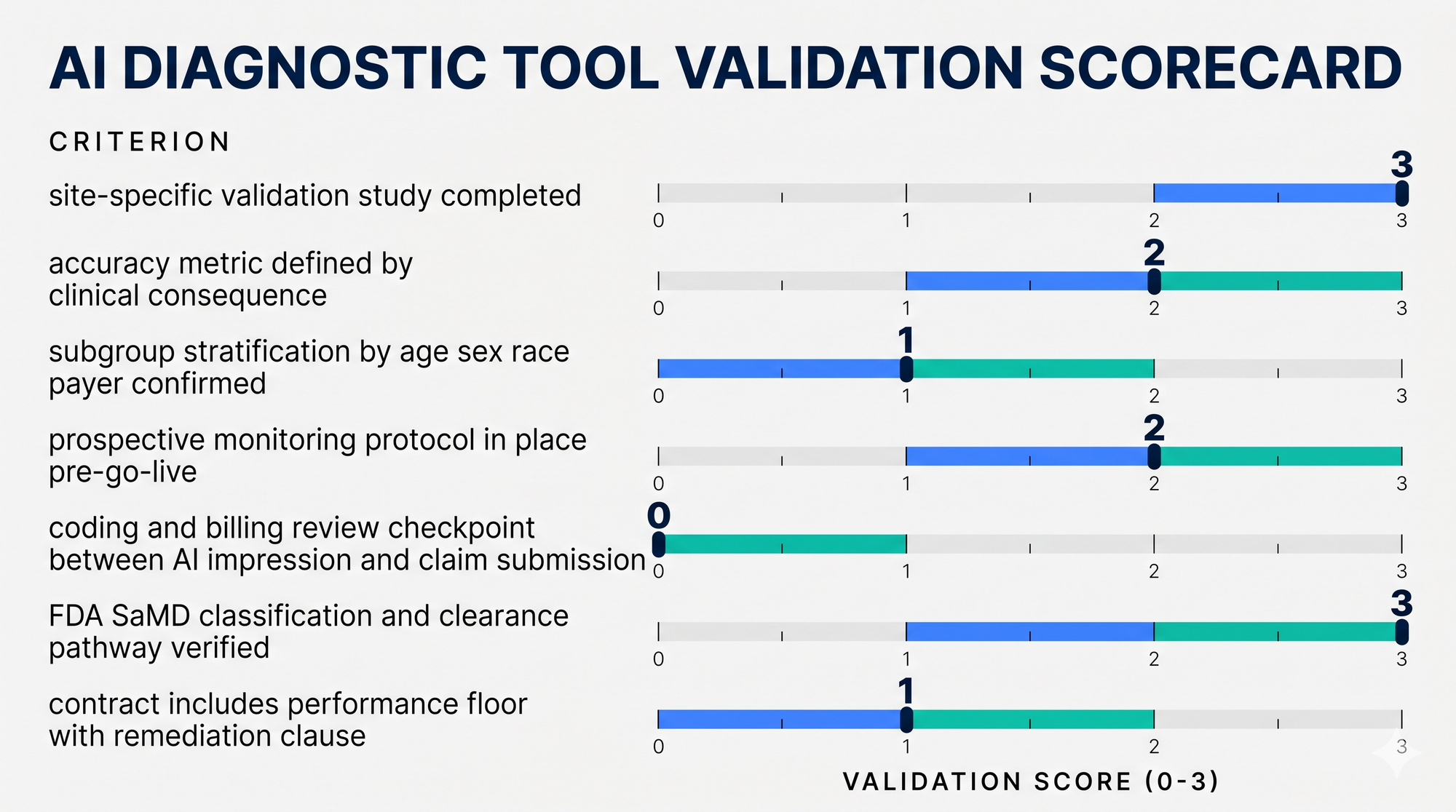
How do you build a tactical AI diagnosis validation framework?
Demand a site-specific validation study before any contract signature. The vendor's benchmark study is a starting point, not evidence of performance in your population. Require prospective validation on a representative sample of your own patient records, minimum 500 cases, stratified by age, sex, race/ethnicity, and payer mix.
Define your accuracy threshold by clinical consequence, not by vendor benchmark. A false negative rate that is acceptable for low-acuity screening is catastrophic for ED triage. Make the vendor define sensitivity and specificity at the operating threshold they recommend, not the threshold that maximizes their AUC.
Build a monitoring protocol before go-live, not after. Track model performance quarterly. Compare AI impression to final coded diagnosis. Flag drift. If you do not have the internal capacity to do this, your documentation QA partner should be scoped to cover it.
Stratify your pilot population. If your patient panel is 40% Medicaid, 30% Medicare, and skews toward comorbidity-heavy older adults, your pilot cohort needs to reflect that, not the healthiest, clearest-case patients who will make the tool look good.
Separate the diagnostic layer from the coding and billing layer. An AI impression that is wrong has downstream consequences for DRG assignment, risk adjustment, and audit exposure. Your revenue integrity workflow needs a human review checkpoint between AI-generated impression and code submission. See related guidance from CMS on quality measure validation and our internal denial management KPIs breakdown.
How Adentris helps
Adentris documentation QA and revenue integrity workflows include a specific review layer for AI-assisted documentation environments, flagging discordance between AI-generated clinical impressions and final coded diagnoses before claims go out the door. Our QA review module evaluates clinical documentation against payer-defensible standards (ASAM criteria, medical necessity, level-of-care justification, coding support) and the workflow does not care whether the underlying note was written by a clinician, generated by an AI scribe, or some hybrid. The review surfaces the gap either way.
For health systems and BH/SUD facilities deploying AI-assisted documentation tools, the practical engagement is a pre-deployment baseline review, post-deployment gap measurement against that baseline, and a quarterly QA cadence that catches drift as the AI vendor updates its model. This is the layer the vendor benchmark study can't give you, and it determines whether the AI tool is actually saving you money or just shifting your audit exposure downstream. Book a 30-minute demo before your next AI diagnostic tool goes live, not after your first RAC audit.
Frequently Asked Questions
Does FDA clearance mean a diagnostic AI tool is accurate for my patient population?
No. 510(k) clearance establishes substantial equivalence to a predicate device. It does not validate performance in your specific patient mix.
How do I read an AI diagnostic study without a PhD in statistics?
Four questions: What was the dataset source and size? Who were the comparator physicians and what information did they have? What accuracy metric is being reported and at what operating threshold? Was performance stratified by patient subgroup?
Can diagnostic AI create coding and billing liability?
Yes. If an AI-generated impression is accepted without physician review and coded directly, you own the code. If the impression was wrong and the code is wrong, that is a false claim risk under the False Claims Act.
What is a reasonable validation timeline before deploying a diagnostic AI tool?
Minimum 90 days of prospective shadow mode. AI generates impression, physician decides independently, results compared. Shorter timelines are a vendor convenience, not a clinical safety standard.
Is AI-assisted documentation the same risk profile as diagnostic AI?
Different vector, similar exposure. AI scribes don't typically issue diagnoses, but the documentation they produce supports the codes you bill. If the note doesn't carry the weight the code requires, you have a denial and audit problem regardless of who wrote the words.
